DeviceDesign Struct Reference
Detailed Description
Overview
The Fennel device library encapsulates operating system support for devices accessed by higher-level Fennel components. Currently, the only support is for random-access file storage devices. Raw device and network support may be added eventually. The exposed interfaces are tailored for use in a database cache, but can be used in any context where efficient scatter/gather asynchronous I/O is desired.
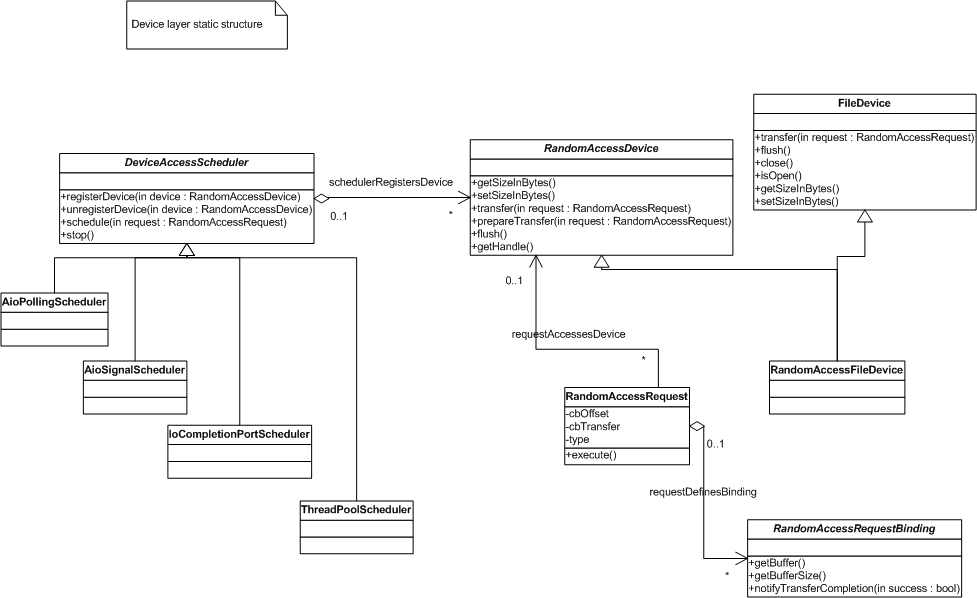
The diagram below illustrates the static structure of classes and interfaces making up the device library:
RandomAccessDevice encapsulates an operating system handle corresponding to some underlying unit of logically contiguous random-access storage (file, raw device, etc.). Public methods are provided for device management and data transfer. However, the data transfer methods are not intended to be used directly (TODO: make that part of the interface only accessible to friends.) Instead, data transfers must be initiated via the DeviceAccessScheduler interface.
Request Scheduling
A DeviceAccessScheduler instance processes requests for a set of registered devices. The request scheduling interface is asynchronous-only, although ThreadPoolScheduler provides an implementation for operating systems on which no efficient asynchronous I/O API is available. The representation for individual requests is via instances of the RandomAccessRequest and RandomAccessRequestBinding classes. RandomAccessRequest specifies:
-
a reference to the RandomAccessDevice on which the transfer should take place
-
a 0-based byte offset into the device data (64-bit)
-
number of bytes to transfer (64-bit)
-
type of transfer (READ or WRITE)
-
a list of RandomAccessRequestBinding instances specifying the mapping from device storage to virtual memory locations (making possible scatter/gather transfers)
In addition, RandomAccessRequestBinding specifies:
-
the start address of a virtual memory location (the transfer source for WRITE; the transfer target for READ)
-
number of bytes to transfer for this binding
-
a virtual notification method to be called when the transfer completes (each binding get its own notification)
Some asynchronous I/O implementations may impose constraints on the parameters above; e.g. device byte offsets may need to be sector aligned, and virtual memory addresses may need to be aligned to some page allocation unit.
Asynchronous API Implementation
True asynchronous request processing is illustrated in the following sequence diagram:
Notes:
-
Processing starts with some external object (requestInitiator in the diagram) initializing an instance of RandomAccessRequest (plus RandomAccessRequestBinding list) with the parameters of the transfer. The initiator must ensure that the request instance remains valid and unmodified for the duration of the transfer. DeviceAccessScheduler does not manage request object lifetimes.
-
This RandomAccessRequest is then passed to the schedule method of a DeviceAccessScheduler instance associated with the RandomAccessDevice being read or written.
-
The scheduler calls the prepareTransfer method of the RandomAccessDevice to give it a chance to set any device-specific parameters needed for the request.
-
The scheduler makes an implementation-specific operating system API call to initiate an asynchronous I/O operation. Note that this means that implementations of DeviceAccessScheduler and RandomAccessDevice are not entirely independent.
-
FIXME: show return from schedule in diagram, and requestInitiator going off to do something else
-
The operating system processes the request. When it completes, it calls back to implementation-specific code in the DeviceAccessScheduler instance. This callback results in corresponding invocations of notifyTransferCompletion on each of the RandomAccessRequestBindings defined by the request. Note that the execution context here varies by the implementation of DeviceAccessScheduler: it could take place in a dedicated event queue thread, signal handler, or whatever. This may impose constraints on the actions that can be safely performed in the notification handler.
The sequence above is used by the following implementations:
-
AioPollingScheduler (on Linux and Solaris) uses lio_listio and aio_suspend polling from a single dedicated thread.
-
AioSignalScheduler (on Solaris) uses aio_read/aio_write and sigaction, with signal handlers running in a dedicated thread pool.
-
IoCompletionPortScheduler (on Windows) uses CreateIoCompletionPort, and ReadFile/WriteFile, with GetQueuedCompletionStatus polling from a dedicated thread pool.
Synchronous API Implementation
The internal sequencing for ThreadPoolScheduler is different:
-
Request initialization and the call to the scheduler interface are the same as with the asynchronous implementations.
-
Internally, ThreadPoolScheduler maintains a thread pool and request queue. When it receives a schedule call, it breaks up the request into individual mini-requests for each of the bindings, inserts these into the queue, and signals any waiting threads to wake up and process them. If all threads are busy, the queue will grow and the requests won't be processed until previous requests complete.
-
When a pool thread removes a request from the queue, it calls the transfer method of the associated RandomAccessDevice. This is a synchronous call which does not return until the request completes. After the request completes, the pool thread calls notifyTransferCompletion on the binding and then goes back to the queue for a new request.
Other Classes
See FileDevice, RandomAccessFileDevice, DeviceMode, and RandomAccessNullDevice for descriptions of some of the other classes provided by the device library.
Examples
For a simple example of device library usage, see TestRandomAccessFileDevice. For a more complicated example, see CacheDesign (TBD).
Dependencies
The device library depends on the common and synch libraries (TODO: links).
Definition at line 222 of file DeviceDesign.cpp.
The documentation for this struct was generated from the following file:
Generated on Mon Jun 22 04:00:29 2009 for Fennel by
 1.5.1
1.5.1