The Fennel segment library defines mechanisms for mapping from logical storage spaces to the physical storage interfaces defined by the device layer (as described in DeviceDesign). Here's a rough analogy to non-persistent memory:
However, the analogy is not exact, since the mapping from virtual to physical can be arbitrarily defined by each segment implementation, along with extra semantics such as versioning. Also, there may be multiple layers of segment virtualization rather than a direct logical-to-physical mapping.
The segment library also relies on the cache library (TBD: link to cache design) for all device access, and for imposing rules such as write ordering.
For an example of how the segment library can be applied to create page-based persistent data structures, see this HOWTO doc.
The Segment interface provides the basic definition of a logical storage space. Some aspects of this interface are optional (meaning implementations are free to raise exceptions when an unsupported or irrelevant capability is requested). Derived classes augment the Segment interface with additional methods. The base public Segment interface methods can be categorized as follows:
Subsequent sections describe the available implementations of Segment. These classes cannot be instantiated directly; instead, SegmentFactory provides methods for this purpose, and for some related functionality:
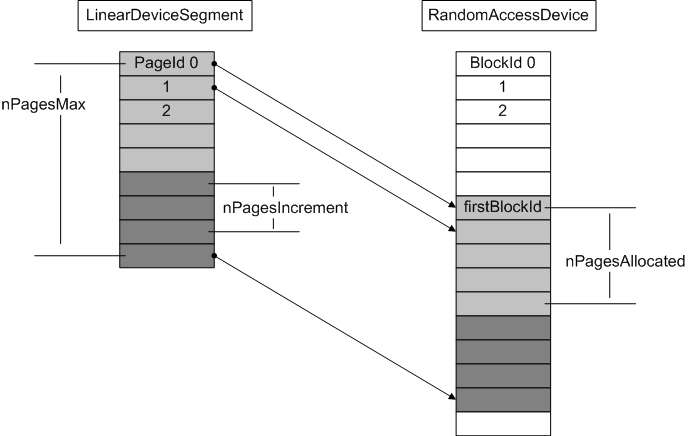
LinearDeviceSegment maps a range of linear PageId's to contiguous blocks of a RandomAccessDevice. The diagram below shows the most general case:
In this example, the segment currently has five pages allocated (the light gray rectangles). The start of the segment does not have to coincide with the start of the device; this is controlled by the firstBlockId parameter. The white blocks are inaccessible via this segment; they could be unused, or allocated to other segments. The dark gray rectangles represent blocks which could be allocated in the future, up to the nPagesMax limit.
The device size only needs to be big enough to contain the allocated pages. If nPagesMax is beyond the end of the device, then the segment will attempt to expand the device when necessary for allocation of new pages, in chunks determined by the nPagesIncrement parameter.
LinearDeviceSegment can be used directly to store data structures with predictable allocation patterns (e.g. a fixed-size hash table), or as a basis for the more complex segments described later.
RandomAllocationSegment implements random page allocation/deallocation in terms of an underlying linear segment (in the simplest case, directly on top of a LinearDeviceSegment). PageId 0 is reserved as a segment map. The rest of the segment is divided up into extents, each headed with an extent map page, as shown in the following diagram:
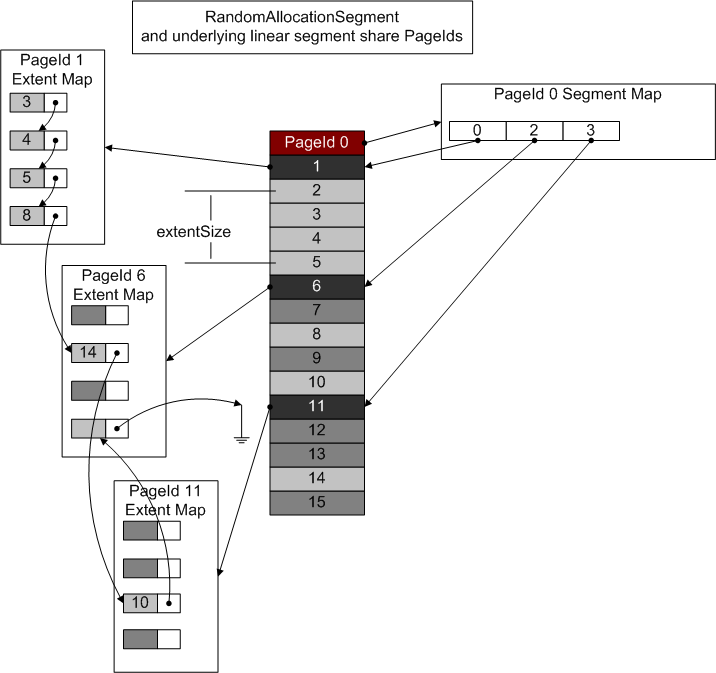
Here, each extent contains one extent map page followed by four data pages; real extents are much bigger. The entries in the PageId 0 segment map page contain the number of unallocated pages in each extent (light gray rectangles represent allocated blocks). Each extent map contains the allocation status of the corresponding data pages, together with successor PageId entries, forming singly-linked lists terminated with NULL_PAGE_ID). Storing the successor chain in the extent map allows for efficient prefetch even in the presence of fragmentation. In this example, the successor sequence is 2,3,4,5,8,14,10. The first extent is compact, but the last two extents are fragmented.
Not shown is an additional field which allows an owner ID to be recorded together with each page allocation in an extent map. This field is also interpreted as the actual allocation status (with a reserved owner ID representing an unallocated page).
TODO: This can be used for storage integrity verification and repair, as well as efficient wholesale deallocation of complex structures.
For very large segments, multiple segment map pages may be required. These are interspersed before each run of extents (rather than all at the beginning after PageId 0) in order to allow a segment to grow without bound. The last segment map page is marked to indicate that there are no more.
The extent size and number of extents per segment map page are fixed based on:
The exact formulas used are in the constructor (RandomAllocationSegment::RandomAllocationSegment). Here's an example calculation:
If the underlying segment supports it, a RandomAllocationSegment can grow whenever all of its initial allocation is exhausted. Growth is in increments of one extent at a time. When an entire segment map page is full (all extents allocated), a new segment map page with one empty extent is allocated.
RandomAllocationSegment is good for implementing dynamic data structures such as BTrees where the page allocation/deallocation pattern is unpredictable.
VersionedRandomAllocationSegment and SnapshotRandomAllocationSegment are companion segments that implement snapshot-consistent, multi-versioned, random data access. VersionedRandomAllocationSegment provides the underlying multi-versioned, random data storage, while SnapshotRandomAllocationSegment maintains transaction private state, initiates the commit and rollback of changes in the underlying segment, and determines which snapshot pages to access for a specified transaction.
VersionedRandomAllocationSegment is derived from the same base class used to implement RandomAllocationSegment. Therefore, it uses the same page allocation/deallocation scheme. In fact, it uses the same segment map described earlier, and a similar extent map. The difference is the entries in a VersionedRandomAllocationSegment extent map include a commit sequence number, corresponding to when the page was committed, and a version chain that links a page to its snapshots. The first entry in the chain is the anchor page and corresponds to the original copy of the page. The page chained from that anchor page entry is the latest snapshot copy of the page. Chained from that is the next latest snapshot copy and so forth, until we chain back to the anchor page.
In order to support recovery and transaction rollbacks, changes made to the segment and extent maps of a VersionedRandomAllocationSegment are not written to the segment's pages until a transaction is committed. This is implemented by maintaining temporary copies of the pages containing these maps. As new pages are allocated, the allocations are reflected in these temporary pages. Only when a transaction commits are the changes corresponding to that transaction copied back to the permanent pages in the VersionedRandomAllocationSegment. In the case of rollback, any uncommitted changes corresponding to the transaction are removed from the temporary pages. All page allocations will go through these temporary pages. That way, all page allocations are still reserved to prevent other transactions from allocating the same page.
SnapshotRandomAllocationSegment is responsible for maintaining and keeping track of page allocations, deallocations, and updates for a specific transaction. This is in contrast to VersionedRandomAllocationSegment which maintains page allocations and deallocations for all active transactions. Normally, you will have one SnapshotRandomAllocationSegment per transaction with more than one SnapshotRandomAllocationSegment associated with the same underlying companion VersionedRandomAllocationSegment. The SnapshotRandomAllocationSegment is created with an initial commit sequence number. This commit sequence number determines which pages should be read by the segment. In order to locate the appropriate snapshot page, it compares this commit sequence number against the commit sequence numbers stored in the extent map entries in the underlying VersionedRandomAllocationSegment. Pages are always accessed through their original anchor page. Therefore, the desired page is found by walking the page chain starting at the anchor until we find a page whose commit sequence number is less than or equal to the commit sequence number associated with the segment. We can walk the chain in this way because as noted above, the chain is constructed such that the pages that follow the anchor are arranged from newest to oldest.
A new snapshot page is created whenever a page is updated. With a SnapshotRandomAllocationSegment, the very first time a page is updated by the segment, it will create a new snapshot copy of the page, linking the new page into the page chain of the original anchor page in the VersionedRandomAllocationSegment. Subsequent updates made through the segment to that same page will not result in a new page allocation. Instead, the previous, newly allocated page will be used since the update is part of the same transaction.
Commits and rollbacks of changes stored in the temporary pages of the underlying VersionedRandomAllocationSegment are initiated through the SnapshotRandomAllocationSegment. When a commit is called on a SnapshotRandomAllocationSegment, it will call its underlying VersionedRandomAllocationSegment to make any page allocations and deallocations that it initiated permanent. When committing these changes, a new commit sequence number is passed down to VersionedRandomAllocationSegment so the extent page entries corresponding to these modifications will reflect the sequence number at the time of the commit, rather than at the start of the transaction.
The following example illustrates these concepts. Suppose the following:
The extent map entries for these pages would be as noted in the diagram below. For simplicity, for each page entry, I only show the commit sequence number and the version chain pointer. Note that because pages 1, 2, and 8 have not been updated, their page entries chain back to themselves.
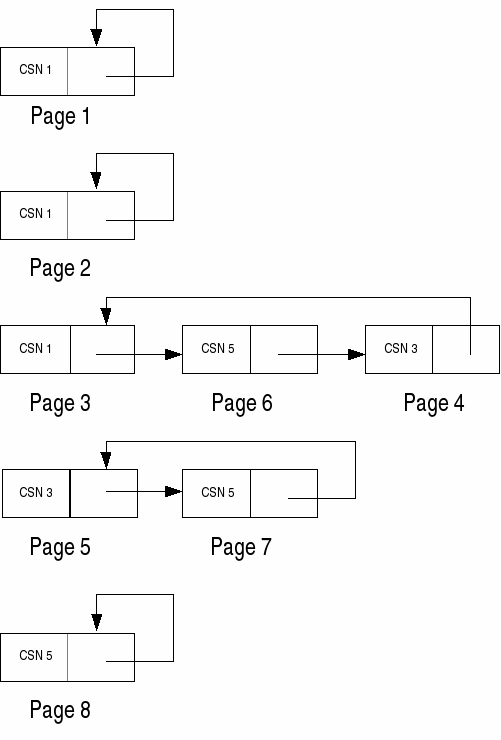
Using the above example:
If you want to tie more than one SnapshotRandomAllocationSegment (each corresponding to a different transaction over time) to the same object, one way of doing this is to make use of a DynamicDelegatingSegment. Unlike a DelegatingSegment, you can dynamically set the underlying delegate in a DynamicDelegatingSegment. In other words, as you switch to a new transaction, you can switch the delegate of a DynamicDelegatingSegment to the SnapshotRandomAllocationSegment corresponding to the new transaction.
One other noteworthy characteristic of VersionedRandomAllocationSegment is the manner in which page deallocations are handled. Requests to deallocate individual pages are still carried out by calling the deallocatePageRange method. However, for the VersionedRandomAllocationSegment, that method does not actually free the page, making it available for re-allocation. Instead, the page is marked as deallocation deferred. In order to free deallocation-deferred pages, VersionedRandomAllocationSegment::getOldPageIds must first be called to locate these pages. Then VersionedRandomAllocationSegment::deallocateOldPages must be called to do the actual frees. Normally, these two methods should be called in a loop until getOldPageIds can no longer find any old pages.
In addition to identifying pages marked for deallocation, VersionedRandomAllocationSegment::getOldPageIds also identifies pages in a page chain that are no longer being accessed by any active transactions. Some of the old Pages in a page chain can be deallocated provided there are at least three old pages in the page chain. Why three?
Using the example from earlier, if we consider the page chain with page 3 as its anchor and the oldest, active transaction id is 5, then no pages can be freed because transaction id 5 is still referencing page 4, and transaction id 6 and beyond are referencing page 6. On the other hand, if the oldest, active transaction id is 7, then we can free page 4. Again, we cannot free page 6 because transaction id 7 is still referencing it. If the page chain contained additional old pages following page 4 in the chain, those pages would also be freed.
CircularSegment implements "infinite" page allocation in terms of a fixed-size underlying linear segment via wrap-around (so CircularSegment PageId x corresponds to PageId x modulo n in the underlying linear segment, where n is the fixed size). Allocation fails if old pages are not deallocated soon enough. The diagram below provides an example:
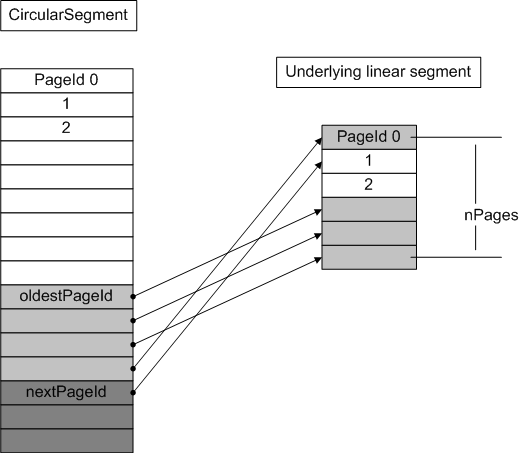
CircularSegment is good for implementing logs (but requires regular checkpointing in order to free log space).
VersionedSegment and WALSegment collaborate to provide a rudimentary page-based versioning and recovery scheme. (Currently the versioning is only used internally for recovery, and only two versions are maintained, but eventually online multi-versioning may be exposed for application use). The recovery guarantee made by VersionedSegment is that after a crash it can be restored to the exact physical state written at the time of a checkpoint prior to the crash. (This may be the last checkpoint or the penultimate checkpoint depending on the checkpoint type, as discussed later.)
VersionedSegment stores data pages in an underlying segment of any kind. It stores log pages in a separate WALSegment, which provides the bookkeeping needed to implement the write-ahead logging protocol. WALSegment requires its underlying segment to support ascending (but not necessarily linear) allocation with successor support. The diagram below shows the state of a VersionedSegment after several checkpoints:
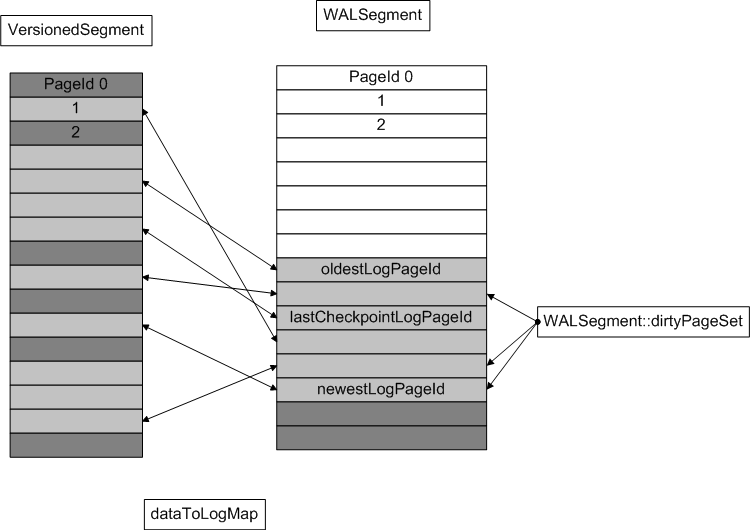
Some allocated pages are clean, meaning they have not been modified since the last checkpoint, and hence have no corresponding pages in the WALSegment. Others are dirty and have corresponding log entries. The association between data and log pages is two-way; the data-to-log direction is stored in an in-memory table (dataToLogMap), but the log-to-data direction is stored persistently via the footer of each logged page; this footer also records the page version number and checksum for use during recovery. In addition, WALSegment maintains a dirtyPageSet automatically by implementing the cache's MappedPageListener interface. This allows VersionedSegment to determine whether the log page for a given dirty data page has been flushed yet; if not, VersionedSegment prevents the cache from flushing the data page by overriding MappedPageListener::canFlushPage. VersionedSegment also overrides MappedPageListener::notifyPageDirty to intercept each write to a page, giving it a chance to log the clean page data before the write takes place. Logging for a particular page is only required before the first write after each checkpoint, since recovery is not responsible for restoring intermediate states.
Two kinds of checkpoints are supported for VersionedSegments. The simplest is a sharp checkpoint, which has the following sequence:
The large amount of synchronous I/O required for a sharp checkpoint may result in poor throughput, so fuzzy checkpoints are also supported. When fuzzy checkpointing is used, log data spans two checkpoint intervals rather than just one. When a checkpoint is requested, the only data pages that are flushed are those that were also dirty at the time of the previous checkpoint; any others are left dirty in the hope that they will be flushed for other reasons, such as cache victimization, before the next checkpoint. The bookkeeping for this is encapsulated by FuzzyCheckpointSet. After a fuzzy checkpoint, the log cannot be truncated completely; instead, three log PageId pointers are maintained:
During a fuzzy checkpoint, all pages earlier than lastCheckpointLogPageId are deallocated, and the log pointers are shifted so that oldestLogPageId advances to one page past lastCheckpointLogPageId, and lastCheckpointLogPageId advances to newestLogPageId.
TODO: a version/log history diagram is needed to help explain this
Regardless of whether sharp or fuzzy checkpoints were used online, the recovery procedure is always the same:
VersionedSegment can be used for UNDO recovery to restore an action-consistent checkpoint state. More complex transactional guarantees, such as REDO recovery to a last committed state, must be programmed at a higher level (TBD: link to txn design docs). WALSegment can be used independently as part of other logging schemes.
LinearViewSegment allows a linear view to be imposed on top of a random allocation segment. The linear sequence is defined in terms of the successor function, so given the first page in a successor chain, the linear view is constructed by following the chain and building up an in-memory page table for random access, as in the following diagram:
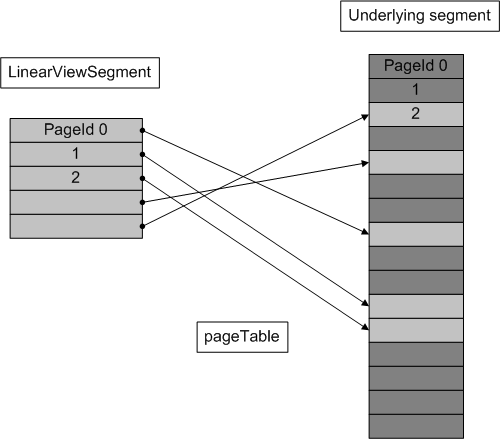
LinearViewSegment is good for storing large dynamically allocated random-access arrays, such as LOB data, in an underlying RandomAllocationSegment.
ScratchSegment is like a ramdisk. Rather than storing data in a device, it allocates scratch pages from the cache. Page contents persist only until the scratch segment is closed, and remain implicitly locked into cache until then.
Scratch page BlockIds reference the cache's singleton instance of the RandomAccessNullDevice. However, these BlockId's are not mapped by the cache, so all access to ScratchSegment pages must go through a special CacheAccessor implementation.
ScratchSegment is useful for creating efficient temporary structures, since it eliminates the overhead associated with persistent page allocation. It can also be useful as a means of managing miscellaneous scratch memory required by a complex process such as a query execution.
Several of the segment types defined above are built on top of another underlying segment. This segment layering can be of arbitrary depth; abstract base class DelegatingSegment makes it easy to create new segment implementations which use layering. The diagram below shows an example of how segments can be layered in interesting ways:
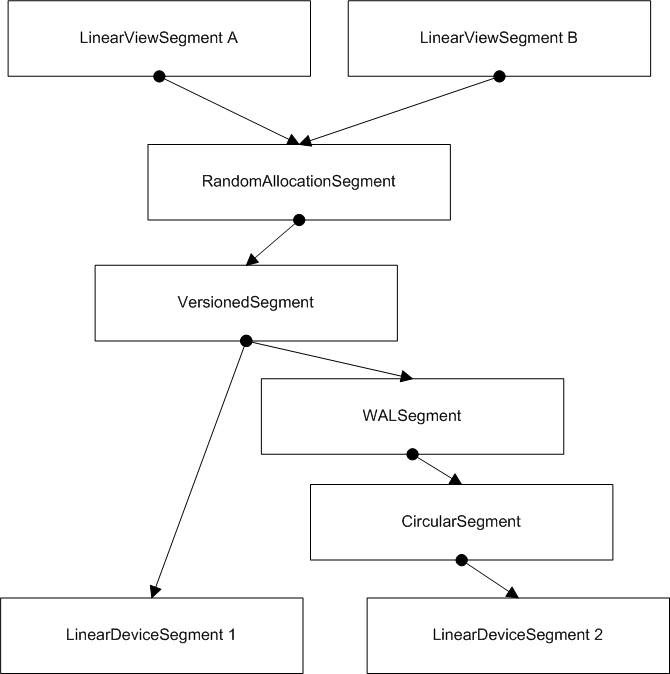
At the lowest level are two LinearDeviceSegments. The first accesses a data device, and the second accesses a log device. The CircularSegment imposes a particular page allocation pattern on the log, while the WALSegment adds the write-ahead logging support required by VersionedSegment. The VersionedSegment combines the data device with the log for physical recovery. On top of this, the pages of the VersionedSegment are interpreted as a RandomAllocationSegment, which is further subdivided by two LinearViewSegments.
Layering order can make a big difference. In this example, since the RandomAllocationSegment is above the VersionedSegment, all pages are versioned, including the segment and extent maps. This is good, since recovery needs to restore these to be consistent with the data page contents. However, in other contexts it might make sense to use versioning above a RandomAllocationSegment, for example to version one fixed-allocation object independently of everything else.
When footers are required by more than one layer, the footers are appended, with the lower layers towards the end of the page. Accordingly, the usable page size is cumulatively reduced. DelegatingSegment ensures that events such as checkpoints and page notifications are propagated through all layers (unless a layer consumes it without forwarding it on to those beneath it). Since cache pages can only be mapped to one segment at a time, they are mapped to the highest layer to guarantee that all layers see notifications.
Layering is designed to allow for abstraction. In the example above, it should be possible to eliminate the CircularSegment to create an ever-growing log instead, without the layers above knowing anything about it.
So far, this document has focused on how various segment implementations map logical pages to physical storage. The segment layer also provides infrastructure useful for the implementation of complex structures stored in segments (e.g. BTrees):
Some segment implementations which will be provided in the future include:
It would be easy to define a CompoundSegment allowing multiple Segments to be combined, but it's probably a better idea to rely on operating system volume management support (with the exception of special cases that can benefit from database-level semantics, such as ping-pong writes for automatic log mirroring).
Definition at line 806 of file SegmentDesign.cpp.
 1.5.1
1.5.1