SchedulerDesign Struct Reference
Detailed Description
Overview
The Fennel execution stream scheduler is responsible for determining which execution streams to run and in what order (and/or with what parallelization). In addition, the scheduler is responsible for the actual invocation of stream execution methods. A more modular design would separate scheduling from execution, but there is currently no justification for the extra complexity this separation would introduce.
As background, please read the ExecStreamDesign first.
Interfaces
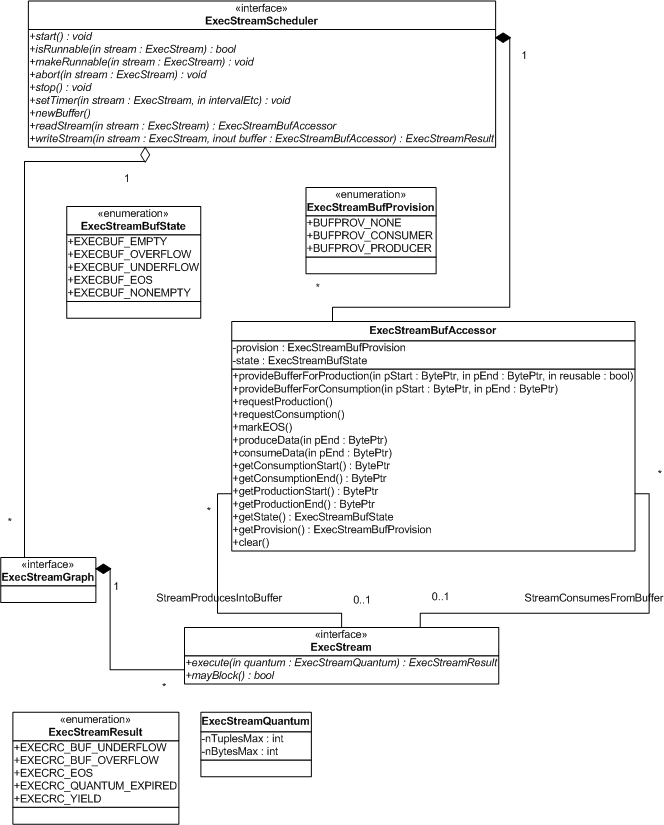
The UML static structure diagram below illustrates the relevant relationships (only attributes and methods relevant to scheduling are shown):
An ExecStreamScheduler may be dedicated per ExecStreamGraph, or may be responsible for multiple graphs, depending on the scheduling granularity desired. Each graph consists of multiple vertex instances of ExecStream, with ExecStreamBufAccessor edges representing dataflow. Each buffer accessor is assigned a single producer/consumer stream pair. Hence, the number of buffers accessible from a stream is equal to its vertex degree in the graph. The design goal is that the ExecStreamBufAccessor representation should remain very simple, with any complex buffering strategies (e.g. disk-based queueing) encapsulated as specialized stream implementations instead.
When the scheduler decides that a particular stream should run, it invokes that stream's implementation of ExecStream::execute, passing a reference to an instance of ExecStreamQuantum to limit the amount of data processed. The exact interpretation of the quantum is up to the stream implementation. The stream's response is dependent on the states of its adjacent buffers, which usually change as a side-effect of the execution. This protocol is specified in more detail later on.
It is up to a scheduler implementation to keep track of the runnable status of each stream. This information is based on the result of each call to ExecStream::execute (including the return code and incident buffer state changes), and can be queried via ExecStreamScheduler::isRunnable. In addition, ExecStreamScheduler::setRunnable can be invoked explicitly to alert the scheduler to an externally-driven status change (e.g. arrival of a network packet or completion of asynchronous disk I/O requested by a stream). A stream may call ExecStreamScheduler::setTimer to automatically become runnable periodically.
Where possible, execution streams should be implemented as non-blocking to ensure scheduling flexibility. Streams that may block must return true from the ExecStream::mayBlock method; schedulers may choose to use threading to prevent invocation of such streams from blocking the execution of the scheduler itself.
Scheduler Extensibility
Most of the interfaces involved in scheduling are polymorphic:
-
Derived classes of ExecStreamScheduler implement different scheduling policies (e.g. sequential vs. parallel, or full-result vs. top-N).
-
Derived classes of ExecStream implement different kinds of data processing (e.g. table scan, sorting, join, etc).
-
Derived classes of ExecStreamBufAccessor may contain additional attributes representing scheduler-specific buffer state (e.g. a timestamp for implementing some fairness policy). Because ExecStreamScheduler acts as a factory for accessor instances, it can guarantee that all of the accessors it manages are of the correct type, and can also create any necessary indexing structures over those accessors for efficiency of the scheduling algorithm.
-
Derived classes of ExecStreamQuantum may provide scheduler-specific quantization limits to streams that can understand it. This requires the code that constructs an ExecStreamGraph to be aware of the kind of scheduler that will be used to execute it. Streams which only understand the generic quantization can be used in any graph.
Top-level Flow
A typical flow for instantiation and scheduling of a single stream graph is as follows:
-
The caller instantiates an ExecStreamGraph together with the ExecStream instances it contains. (See ExecStreamBuilder and ExecStreamFactory.)
-
The caller instantiates an ExecStreamScheduler and associates the graph with it. Internally, the ExecStreamScheduler allocates one instance of ExecStreamBufAccessor for each dataflow edge in the graph (as well as one for each input or output to the graph) and notifies the adjacent streams of its existence. Once a graph and its streams have been associated with a scheduler in this way, they may never be moved to another scheduler. Buffer accessors start out in state EXECBUF_EOS. Buffer provision settings are recorded for use in sanity checking later.
-
The caller invokes ExecStreamGraph::open(). This changes the state of all buffer accessors to EXECBUF_EMPTY.
-
The caller invokes ExecStreamScheduler::start().
-
The caller invokes ExecStreamScheduler::readStream() to read query output data, and/or ExecStreamScheduler::writeStream() to write query input data. This is repeated indefinitely. Optionally, the caller may invoke ExecStreamScheduler::abort() from another thread while a read or write is in progress; the abort call returns immediately, but the abort request may take some time to be fulfilled.
-
The caller invokes ExecStreamScheduler::stop(). This prevents the scheduling of any further streams. For an asynchronous scheduler, this should not return until all execution in other scheduler threads has completed.
-
The caller invokes ExecStreamGraph::close().
When the scheduler invokes a stream, the stream attempts to perform its work, possibly consuming input and/or producing output:
-
The stream tests for the presence of input data by calling getState() on its input buffer accessors.
-
The stream accesses the input data via getConsumptionStart() and getConsumptionEnd(), and consumes it by calling consumeData().
-
When the stream knows that it needs more input data to make progress but the input buffer is empty, it calls requestProduction() to change the state to EXECBUF_UNDERFLOW. If the stream is responsible for providing the input buffer memory, it must call provideBufferForProduction() to set up the memory area which the upstream producer should fill.
-
If the stream is responsible for providing an output buffer, it produces data by calling provideBufferForConsumption(). Otherwise, it produces data by calling getProductionStart() and getProductionEnd() to access the output memory area provided by the downstream consumer, and then calls produceData() to indicate how much of that area it filled. In either case, the resulting state of the output buffer is either EXECBUF_NONEMPTY (data was written) or EXECBUF_OVERFLOW (data was written and output buffer space was exhausted, so requestConsumption() was called).
-
When the stream knows that no more data will ever be produced on a particular output, it calls markEOS() on the corresponding buffer accessor.
-
ExecStreamBufAccessor provides additional convenience methods, including some tuple-level production/consumption calls built on top of produceData/consumeData.
The possible responses from the execute call are enumerated by ExecStreamResult:
-
EXECRC_BUF_UNDERFLOW: the invoked stream ceased execution because it exhausted the data from at least one of its inputs. Note that this does not imply that no output was produced (and this is true for all result codes, including EXECRC_EOS).
-
EXECRC_BUF_OVERFLOW: the invoked stream ceased execution because it exhausted the space in at least one of its output buffers.
-
EXECRC_EOS: the invoked stream ceased execution because it reached the end of all of its inputs.
-
EXECRC_QUANTUM_EXPIRED: the invoked stream ceased execution because its quantum expired.
-
EXECRC_YIELD: the invoked stream ceased execution because it had no more work to do. An example would be a stream which periodically becomes runnable to poll a data source; when no new data is available, EXECRC_YIELD is the appropriate result.
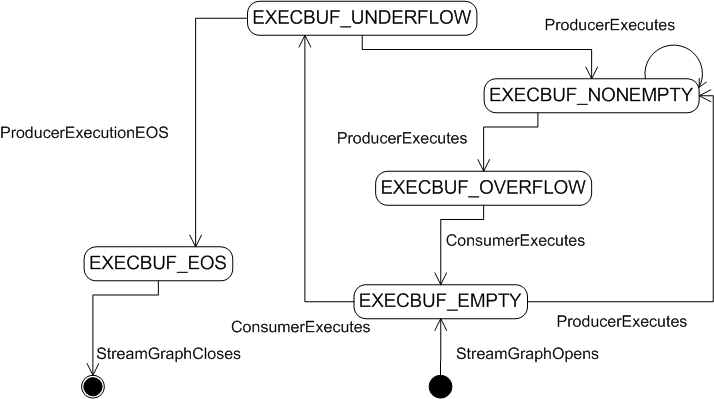
From the point of view of a buffer, this means the possible transitions are as follows:
Note that multi-threaded schedulers must guarantee that both streams adjacent to a buffer are never running simultaneously; this eliminates the need to synchronize fine-grained access to buffer state.
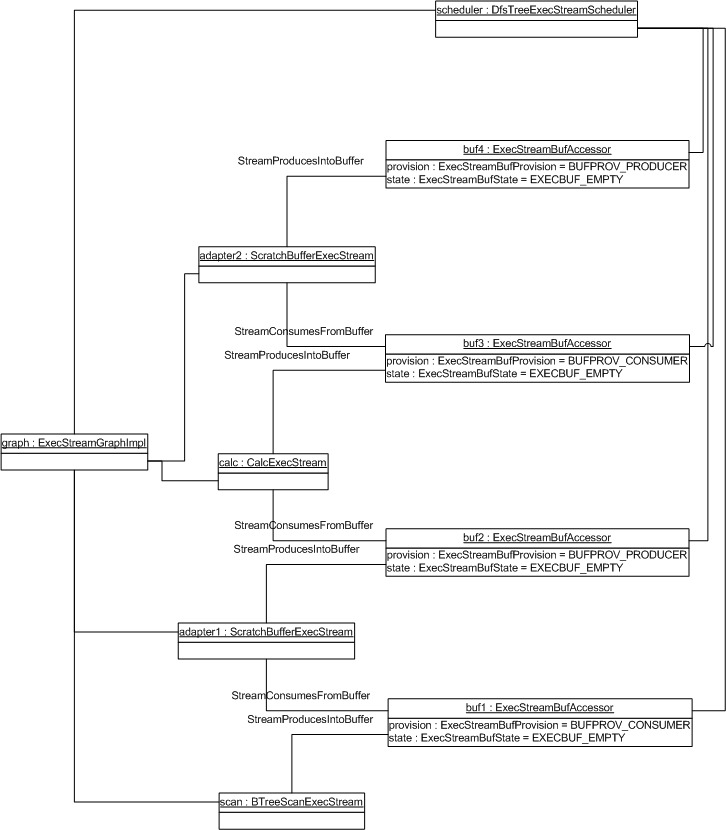
Example Graph
To help explain the abstractions described so far, the UML object diagram below shows a simple query stream graph with associated scheduler and buffers:
This graph corresponds to a simple query like SELECT name FROM emps WHERE age > 30. Note that although four buffer instances are created, the two instances of ScratchBufferExecStream are the only streams that actually allocate any memory. The BTreeScan writes into the memory allocated by adapter1 above it, which is also read by the calculator; the calculator writes into the memory allocated by adapter2 above it, which is also read by the caller via readStreamBuffer.
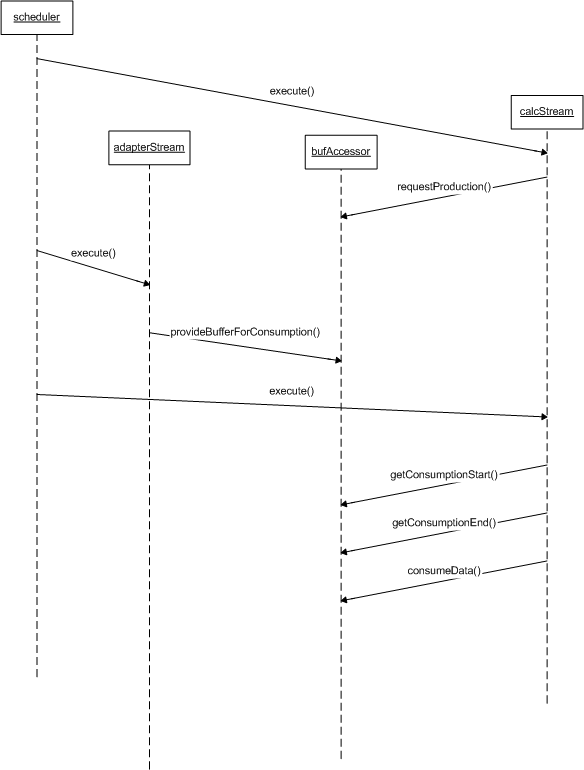
Producer Provision of Buffer Memory
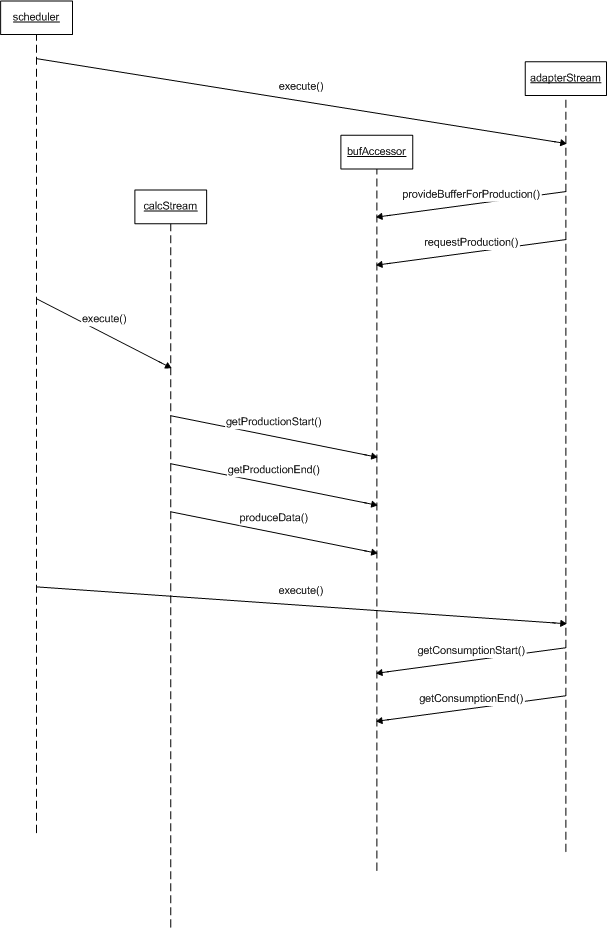
When a buffer accessor's provision mode is set to BUFPROV_PRODUCER, the producer is responsible for providing buffer memory. The diagram below illustrates the call sequence between producer and consumer:
First, the calc stream (the consumer) requests production but does not provide any buffer. Next, the adapter stream (the producer) provides a buffer full of data. Finally, the consumer accesses the data via getConsumptionStart/End, marking how much it read via the consumeData call.
Consumer Provision of Buffer Memory
For BUFPROV_CONSUMER, the call sequence is different:
First, the adapter stream (the consumer) requests production AND provides an empty buffer. Next, the calc stream (the producer) determines the buffer bounds with getProductionStart/End and then writes tuples into the buffer, marking the end of data with the produceData call. Finally, the consumer accesses the data in the buffer via getConsumptionStart/End.
A reference implementation of the ExecStreamScheduler interface is provided by the DfsTreeExecStreamScheduler class, which is suitable as a no-frills implementation of a traditional lazy non-parallel query execution.
The algorithm used by this scheduler is as follows:
-
The start method asserts that each of the graphs associated with the scheduler is a forest of trees (each stream has at most one consumer, and no cycles exist).
-
The readStream() method is the real entry point for synchronous traversal of the tree. (writeStream() is not supported.)
-
The scheduler asserts that the stream with which readStream() was invoked has no consumers (i.e. it is the root of a tree) and has output buffer provision mode BUPROV_PRODUCER. The scheduler also asserts that the root output buffer's state is not EXECBUF_OVERFLOW. A current stream pointer is set to reference this stream, and the output buffer's state is set to EXECBUF_UNDERFLOW.
-
VISIT_VERTEX:
-
The scheduler iterates over each of the input buffers of the current stream in order. If it encounters one having state EXECBUF_UNDERFLOW, the scheduler updates its current stream pointer to the corresponding producer stream, and loops back to label VISIT_VERTEX.
-
The scheduler invokes the current stream's execute method, and asserts that the return code was not EXECRC_YIELD (DfsTreeExecStreamScheduler does not support asynchronous stream execution).
-
If the scheduler's abort flag has been set asynchronously, the traversal terminates.
-
If the return code was EXECRC_BUF_UNDERFLOW, then the scheduler loops back to label VISIT_VERTEX, which will detect the input node which needs to be executed.
-
If the return code was EXECRC_QUANTUM_EXPIRED, then the scheduler loops back to label VISIT_VERTEX, causing the current node to be re-executed for another quantum (DfsTreeExecStreamScheduler always requests an unbounded quantum, so this should rarely happen).
-
If the return code was EXECRC_BUF_OVERFLOW or EXECRC_EOS, then the scheduler updates the current stream pointer to reference the current stream's parent and then loops back to label VISIT_VERTEX. If the current stream has no parent, the traversal terminates instead.
DfsTreeExecStreamScheduler does not support asynchronous runnability changes (setRunnable and setTimer).
Example Exec
Putting together the example graph shown earlier with the DfsTreeExecStreamScheduler algorithm, an example execution trace might read as follows for a table of five rows:
-
caller invokes readStream() on scheduler with adapter2 as argument.
-
scheduler calls execute() on adapter2. adapter2 invokes requestProduction() on buf3 and calls provideBufferForProduction() with its allocated cache page. adapter2 returns EXECRC_BUF_UNDERFLOW.
-
scheduler calls execute() on calc. calc invokes requestProduction() on buf2. calc returns EXECRC_BUF_UNDERFLOW.
-
scheduler calls execute() on adapter1. adapter1 invokes requestProduction() on buf1 and calls provideBufferForProduction() with its allocated cache page. adapter1 returns EXECRC_BUF_UNDERFLOW.
-
scheduler calls execute() on scan. scan calls produceData(), writing five tuples into buf1 and changing its state to EXECBUF_NONEMPTY, and then returns EXECRC_EOS.
-
scheduler calls execute() on adapter1. adapter1 calls provideBufferForConsumption() on buf2, passing it memory references from buf1 and changing its state to EXECBUF_OVERFLOW. adapter1 returns EXECRC_BUF_OVERFLOW.
-
scheduler calls execute() on calc. calc applies filter and calls consumeData() to consumes all rows from buf2, changing its state to EXECBUF_UNDERFLOW. calc writes three rows into buf3, calling produceData() to set its state to EXECBUF_NONEMPTY. calc returns EXECRC_BUF_UNDERFLOW.
-
scheduler calls execute() on adapter2. adapter2 calls provideBufferForConsumption() on buf4, passing it memory references from buf3 and changing its state to EXECBUF_OVERFLOW. adapter2 returns EXECRC_BUF_OVERFLOW.
-
scheduler returns to caller with a reference to buf4.
-
caller calls consumeData() to read the data from buf4, changing its state to EXECBUF_EMPTY.
-
caller invokes readStream() on adapter2 again.
-
scheduler calls execute() on adapter2, which returns EXECRC_BUF_UNDERFLOW; same thing repeats all the way down the tree.
-
scheduler calls execute() on scan, which calls markEOS() on buf1, changing its state to EXECBUF_EOS, and returns EXECRC_EOS.
-
scheduler calls execute() on adapter1, which returns EXECRC_EOS, etc.
-
scheduler calls execute() on calc, which returns EXECRC_EOS, etc.
-
scheduler calls execute() on adapter2, which returns EXECRC_EOS, etc.
-
scheduler returns to caller with a reference to buf4.
-
caller sees EOS state.
TODO: an animated visualization would be more useful.
Note that most real executions will be much more complicated due to joins and partial consumption of input.
Definition at line 417 of file SchedulerDesign.cpp.
The documentation for this struct was generated from the following file:
Generated on Mon Jun 22 04:00:45 2009 for Fennel by
 1.5.1
1.5.1