This document describes the components making up the ExecStream library, which is Fennel's infrastructure for execution of queries and data manipulation. The focus is on theory; for practice, see ExecStreamHowTo.
Fennel queries are physically implemented as dataflow graphs, where each graph vertex is a specialized execution processor called an ExecStream (sometimes also referred to as an execution object or XO). A related collection of streams is manipulated as a unit called an ExecStreamGraph.
Traditional DBMS executors use a tree dataflow structure together with a simple "iterator" model, where a fetch request on a top-level stream is implemented by recursively fetching from lower-level streams until leaves are reached. Fennel departs from this in two important ways:
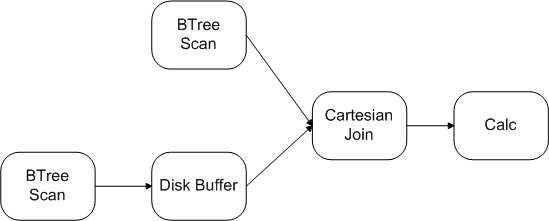
The diagram below illustrates a graph for carrying out a join query:
In this case, the graph structure is a tree, where the "leaves" read from table storage and produce tuples. These tuples flow rightward, getting combined and transformed, until they are emitted by the "root" node (the Calc stream) and returned to the user who issued the query.
NOTE: the DiskBuffer stream implies additional dataflow to and from disk, but this external flow is not managed or understood by the ExecStreamGraph. It is entirely encapsulated by the DiskBuffer stream. Likewise, the BTreeScan streams imply dataflow from disk.
Here is some common ExecStreamGraph terminology:
CartesianJoin and the Calc, but there is no dataflow between the two instances of BTreeScan.
CartesianJoin stream is a producer with respect to the Calc. A producer is upstream from its consumer.
Calc stream is a consumer with respect to the CartesianJoin. A consumer is downstream from its producer.
BTreeScan are sources. When the graph structure is a tree, sources are also referred to as leaves.
Calc stream is a sink. When the graph structure is a tree, the (unique) sink is also referred to as the root.
CartesianJoin is an input to the Calc.
BTreeScan is an output of that scan.
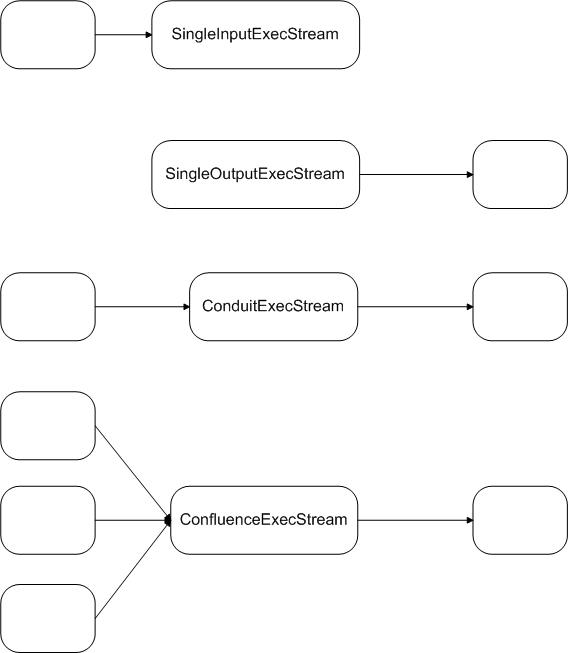
The diagram below shows some typical vertex types used in building query graphs. These are common enough that they have corresponding abstract base classes from which concrete stream implementations derive:
Streams consume tuple data from input buffers and produce tuple data into output buffers. This interaction is mediated by objects known as buffer accessors (encapsulated by class ExecStreamBufAccessor). The buffer access design allows for both by-value and by-reference semantics, with the goal being to minimize the number of copy operations required throughout the tree.
Below is the same graph from the earlier example, but this time embellished with extra buffers and buffer accessors:
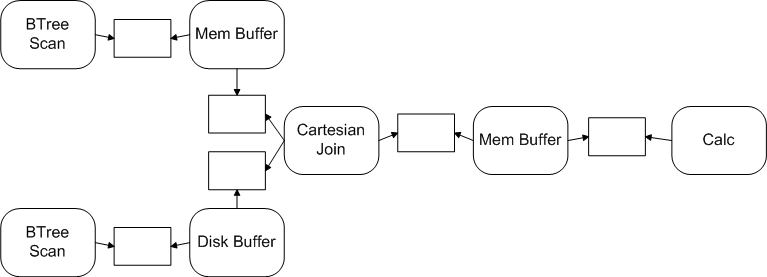
The small rectangles are buffer accessors. One buffer accessor is associated with each dataflow edge, and for each such edge, the producer and consumer streams retain references to the corresponding accessor. Also note that two extra MemBuffer streams have been added to the graph. The job of these "adapter" streams is to allocate memory to be written and read by the adjacent streams. For example, as the CartesianJoin stream produces join tuples, it writes them into the downstream MemBuffer. The Calc stream reads them from that same MemBuffer.
There are no MemBuffer streams adjacent to the DiskBuffer stream. The reason is that the DiskBuffer stream is capable of allocating pages directly from the cache for I/O purposes. It can provide these pages to the BTreeScan for writing, and to the CartesianJoin for reading. This way, two extra copies are avoided. Each stream is responsible for declaring its buffer provisioning requirements so that each dataflow can be optimized automatically.
The ExecStream and ExecStreamGraph classes have a similar lifecyle. An ExecStream is always an element in an ExecStreamGraph; in the simple case this is the same graph, so the lifecycles coincide. It is also possible for a stream to change graphs: that is, it can be constructed in one graph (its preparation context), and then that graph can be merged into a larger graph (its execution context). Note that merger is allowed but not arbitrary edits, which could easily produce an invalid graph. This feature is intended as a basis for query optimization across multiple statements, etc.
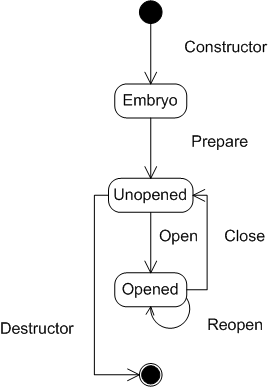
prepare method which precomputes data structures needed during execution
open method which clears stream-specific state and allocates any resources (such as memory, connections, or threads) needed during execution.
For details on how ExecStreams are executed, please see the SchedulerDesign.
Definition at line 273 of file ExecStreamDesign.cpp.
 1.5.1
1.5.1